
앞서 언급했듯이 elasticsearch는 검색엔진이다.
검색엔진이면 당연히 저장되어 있는 데이터들 중 원하는 데이터를 찾아내는 속도가 빨라야 하겠지?
근데 그건 다른 DB들도 마찬가지다.
그렇다면 elasticsearch가 다른 DB랑은 어떻게 다를까?
Elasticsearch는 어떻게 작동하나요?
로그, 시스템 메트릭, 웹 애플리케이션 등 다양한 소스로부터 원시 데이터가 Elasticsearch로 흘러들어갑니다. 데이터 수집은 원시 데이터가 Elasticsearch에서 색인되기 전에 구문 분석, 정규화, 강화되는 프로세스입니다. Elasticsearch에서 일단 색인되면, 사용자는 이 데이터에 대해 복잡한 쿼리를 실행하고 집계를 사용해 데이터의 복잡한 요약을 검색할 수 있습니다. Kibana에서 사용자는 데이터를 강력하게 시각화하고, 대시보드를 공유하며, Elastic Stack을 관리할 수 있습니다.
Elasticsearch 인덱스는 무엇인가요?
Elasticsearch 인덱스는 서로 관련되어 있는 문서들의 모음입니다. Elasticsearch는 JSON 문서로 데이터를 저장합니다. 각 문서는 일련의 키(필드나 속성의 이름)와 그에 해당하는 값(문자열, 숫자, 부울, 날짜, 값의 배열, 지리적 위치 또는 기타 데이터 유형)을 서로 연결합니다.Elasticsearch는 반전된 인덱스라고 하는 데이터 구조를 사용하는데, 이것은 아주 빠른 전체 텍스트 검색을 할 수 있도록 설계된 것입니다. 반전된 인덱스는 문서에 나타나는 모든 고유한 단어의 목록을 만들고, 각 단어가 발생하는 모든 문서를 식별합니다.색인 프로세스 중에, Elasticsearch는 문서를 저장하고 반전된 인덱스를 구축하여 거의 실시간으로 문서를 검색 가능한 데이터로 만듭니다. 인덱스 API를 사용해 색인이 시작되며, 이를 통해 사용자는 특정한 인덱스에서 JSON 문서를 추가하거나 업데이트할 수 있습니다.
출처 : elastic 공식 홈페이지 - https://www.elastic.co/kr/what-is/elasticsearch
Inverted Index
elastic 공식 홈페이지의 설명을 보면 "반전된 인덱스(inverted index)"라는 용어가 나온다. 대충 요약해보면 inverted index를 사용하기 때문에 검색이 빠르다는 얘기인데.. inverted index가 뭘까? 아니 그전에 index는 또 뭘까?
index는 "색인"이라는 뜻이다. 일반적인 RDB를 다뤄본 사람이라면 index의 개념은 어느정도 알고 있을 것이다. index는 RDB에서 쿼리 성능을 향상시키는 기술(?) 중 하나다. indexing이 되지 않은 상태에서 데이터를 조회하게 되면 조회하고자 하는 데이터가 어디에 있는지 모르기 때문에 테이블의 모든 데이터를 다 뒤져보게 된다. 데이터가 총 100개 저장되어 있고 그 중 1개 데이터를 조회할때 최악의 경우엔 100개 데이터를 모두 뒤져봐야 원하는 데이터를 찾을 수 있게 된다는 얘기다.
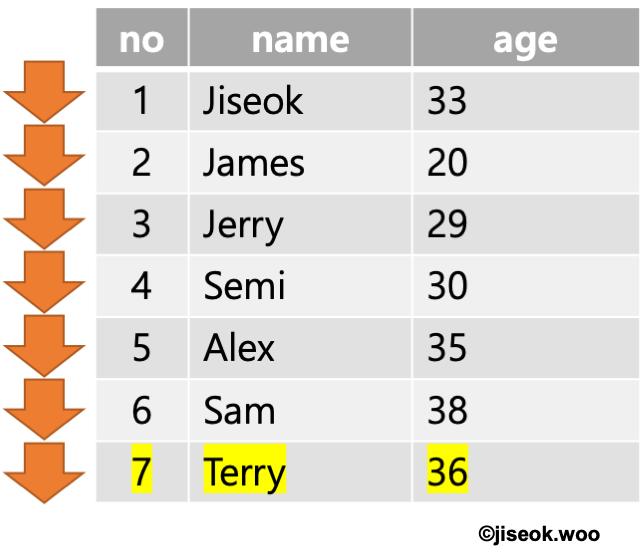
index는 쉽게 말해 목차를 만든다고도 얘기들을 하지만 정확히 말하면 B+ Tree 구조로 별도의 index 테이블을 만든다. 따라서 해당 컬럼 값으로 데이터를 찾거나 정렬을 하게 될 경우 인덱싱이 되지 않았을 때보다 더 빠르게 접근이 가능해진다.

위 트리구조는 예제로 그리다보니 이진트리랑 흡사해지긴 했지만 어쨋든 느낌은 비슷하니까. 저런식으로 특정 컬럼을 기준으로 정렬해 트리구조를 만들어버리면 검색하는데 훨씬 유리해지게 된다. 이게 인덱싱의 원리이다.
inverted index는 반전된 인덱스라고 했다.(역색인 이라고도 한다.) 인덱스는 인덱스인데 반전해서 저장한다? 말그대로다. 보통 데이터가 저장되면 1번째 row에 어떤 데이터가 있다는 식으로 저장이 된다. inverted index는 반대로 어떤 데이터는 몇번째 row에 있다는 방식으로 저장한다.

그냥 index랑 비슷한 것 같은데? 뭐가 더 빠르다는거지?
elasticsearch가 강점을 보이는 부부은 문장이나 여러 단어들의 조합들이 저장될 때이다. 문장은 여러 단어들로 구성이 되어있고 그 중 중요한 키워드도 있고 큰 의미가 없는 단어들도 있다. elasticsearch는 데이터를 저장할때 의미있는 단어들을 추출해 해당 단어들로 inverted index를 생성한다. 그렇게 되면 단어를 검색할때 어떤 데이터들에 해당 단어가 포함되어 있는지 빠르게 확인이 가능해진다.

위에서 보면 "나는 책을 읽는다" 라는 문장은 "나", "책", "읽다" 세개 키워드가 제일 중요한 키워드이다. elastcisearch는 데이터를 저장하기 전에 analyzer라는 친구가 해당 데이터를 분석하고 tokenizer로 적절히 짤라 키워드를 생성해 inverted index로 저장할 수 있도록 해준다. 예를들어 language analyzer의 경우엔 문장을 분석해 "가다", "간다", "갔다" 등을 "가다"로 통일해 키워드를 생성한다. tokenizer는 분석된 문장을 공백이든 -든 기준을 잡아 키워드 단위로 짤라주는 역할을 한다. elasticsearch는 수많은 analyzer와 tokenizer가 존재하며 이를 잘 활용해야 elasticsearch를 제대로 활용한다 볼 수 있겠다.
자, 다시 위의 예를 봐보자. "나는 책을 읽는다."와 같은 문장들이 저장되어 있고 그 중 "영화"라는 단어가 들어간 데이터만 찾고 싶을때 옆의 inverted index 테이블을 보면 누가봐도 한눈에 아주 쉽게 "영화" 라는 단어가 어디에 있는지 확인할 수 있다. 이게 elasticsearch에서 말하는 inverted index이고 elasticsearch가 검색엔진으로써 빠른 검색이 가능한 이유이다.
이정도면 대충 elasticsearch가 어떤 느낌인지 정도는 파악된 것 같다.
다음 포스팅부터는 실제 elasticsearch를 실습하기 위한 환경을 구성해봐야겠다.
'elastic-stack' 카테고리의 다른 글
| VM을 활용한 Elastic Stack 실습 환경 구축 1 - VM 생성하기 (2) | 2020.01.11 |
|---|---|
| Elasticsearch의 shard와 replica (0) | 2020.01.11 |
| Elasticsearch의 Cluster와 Node 개념 (0) | 2020.01.10 |
| Elasticsearch 실습 환경에 관해서.. (0) | 2020.01.05 |
| Elasticsearch? Kibana? Logstash? - Elastic Stack (0) | 2020.01.05 |




댓글